Scaling PostgreSQL Connections in Azure: A Deep Dive into Multi-PgBouncer Architectures

1. Introduction
In today's data-driven landscape, the demand for highly available and scalable database architectures is not just a preference—it's a fundamental requirement. For applications leveraging PostgreSQL, especially within dynamic cloud environments like Microsoft Azure, efficient connection management becomes a critical pillar supporting both performance and resilience. This article provides a deep dive into architecting a robust, scalable, and highly available connection pooling layer for Azure Database for PostgreSQL - Flexible Server. We'll explore how to deploy multiple PgBouncer instances, orchestrated by an Azure Load Balancer, to transcend the limitations of single poolers, overcome single points of failure, and achieve significantly enhanced throughput for your demanding workloads.
2. The Double-Edged Sword: PostgreSQL Connections & the Imperative of Pooling
PostgreSQL's power and flexibility are undeniable, but like any sophisticated system, it has operational nuances. One such area is connection management. Each new client connection to a PostgreSQL server consumes resources—memory and CPU cycles—for process spawning and state management. While Azure Database for PostgreSQL - Flexible Server offers various instance sizes, each with a corresponding max_connections limit (e.g., a General Purpose, 2 vCore instance might allow a few hundred connections, while larger instances allow more), naively allowing every application instance or microservice to open its own direct connection can quickly lead to issues. High connection churn, where connections are frequently opened and closed, exacerbates this, leading to performance degradation, resource exhaustion on the database server, and potential "connection storms" during peak loads.
This is precisely where connection pooling steps in. Imagine an express lane at a supermarket: instead of every shopper waiting for a new checkout lane to open just for them, a set of lanes are always open, efficiently serving customer after customer. Connection pooling operates on a similar principle. A connection pooler maintains a "pool" of physical database connections that are kept alive and ready. Applications connect to the pooler, which is a very lightweight operation. The pooler then assigns a pre-established physical connection from its pool to the application's session. When the application is done, the connection is returned to the pool, ready for another client, drastically reducing the overhead of new connection establishment on the database server itself.
3. PgBouncer: The Popular Gatekeeper
Enter PgBouncer, a lightweight and highly popular connection pooler for PostgreSQL. It sits between your application and your PostgreSQL server, managing pools of connections and significantly reducing the resource strain on the database. PgBouncer is renowned for its low overhead and extensive configuration options.
It offers three primary pooling modes:
Session Pooling: A client gets a dedicated server connection for the lifetime of its connection to PgBouncer. This is the most compatible but least aggressive in terms of connection reduction if clients hold connections for long periods.
Transaction Pooling: A server connection is assigned to a client only for the duration of a transaction. Once the transaction (BEGIN/COMMIT/ROLLBACK) completes, the server connection is returned to the pool. This mode is highly effective for applications with frequent, short transactions and is often the sweet spot for web applications.
Statement Pooling: The most aggressive mode. Server connections are returned to the pool after each statement. This mode has strict limitations (e.g., multi-statement transactions are disallowed) and is suitable only for specific use cases, typically involving AUTOCOMMIT behavior.
While PgBouncer brings immense benefits, deploying a single PgBouncer instance, especially in a production environment demanding high availability, introduces its own Achilles' Heel: it becomes a potential Single Point of Failure (SPOF). If that single PgBouncer VM or service crashes, all application connectivity to the database is severed, even if the backend PostgreSQL server is perfectly healthy. Furthermore, a single PgBouncer instance can hit CPU or resource limits on its host VM, becoming a performance bottleneck.
4. From SPOF to Scale-Out: The Case for Multiple PgBouncer Instances
The limitations of a single PgBouncer instance—namely the SPOF risk and potential performance bottlenecks—pave the way for a more resilient and scalable architecture: deploying multiple PgBouncer instances. This approach directly tackles these challenges.
Addressing the Single Point of Failure (SPOF): This is the paramount motivation. If one PgBouncer instance in a multi-instance setup fails (e.g., due to a VM crash, process error, or during maintenance), other instances remain operational, and client connections can be seamlessly routed to them. This dramatically improves the availability of your database connection infrastructure.
Achieving High Availability for the Pooling Layer: By distributing PgBouncer instances, ideally across different fault domains or Availability Zones in Azure, the pooling tier itself becomes highly available. The failure of one component no longer means a complete outage for your application's database access.
Horizontal Scalability:
A single PgBouncer process, while efficient, is typically single-threaded per database/user pair defined in its configuration. This, along with the CPU and memory resources of its host VM, can cap its throughput. By deploying multiple PgBouncer instances, you distribute the connection pooling load. More clients can be served, and more transactions can be processed through the pooling layer, effectively scaling out your connection handling capacity.
Simplified Maintenance:
Need to patch the OS on a PgBouncer VM? Want to update the PgBouncer software itself or tweak its configuration? With multiple instances, you can perform rolling updates. One instance can be taken out of service, updated, and brought back online, while the remaining instances continue to handle the load, ensuring zero downtime for your applications.
To orchestrate this distributed setup and provide a single, stable endpoint for your applications, we introduce a Load Balancer. In simple terms, a load balancer acts as a traffic manager. It receives incoming connection requests from clients and intelligently distributes them across a group (or "pool") of backend servers—in our case, the multiple PgBouncer instances. Critically, a load balancer also performs health checks on these backend instances. If a PgBouncer instance becomes unresponsive, the load balancer will stop sending traffic to it, automatically routing connections to the healthy instances. For our Azure-based solution, Azure Load Balancer (Standard SKU) is the ideal choice.
5. Architecting for Resilience & Scale: Multi-PgBouncer with Azure Load Balancer
With the "why" firmly established, let's design the "how." Architecting a multi-PgBouncer setup in Azure involves thoughtfully combining several Azure services to create a resilient and scalable connection pooling layer for your Azure Database for PostgreSQL - Flexible Server. The core principle is to distribute PgBouncer instances and front them with a load balancer. The primary method we'll discuss involves Azure Virtual Machines, followed by an alternative using Azure Kubernetes Service (AKS).
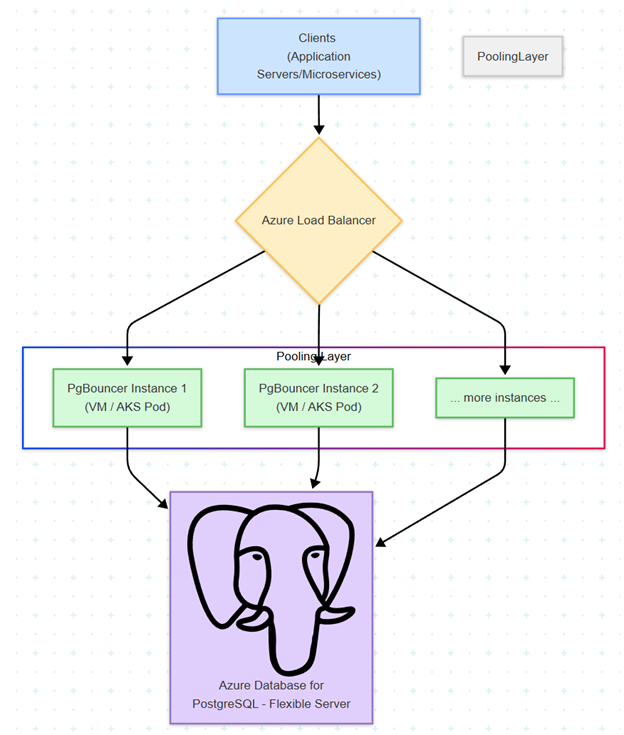
Conceptual Architecture:
Regardless of whether you use VMs or containers for PgBouncer, the high-level architecture remains consistent:
Clients: Your application servers, microservices, or client machines.
Pooling Layer:
An Azure Load Balancer acting as the single, highly available entry point.
A backend pool consisting of multiple PgBouncer instances. These instances can be hosted on Azure Virtual Machines or as pods within an Azure Kubernetes Service cluster.
Database Layer: Your Azure Database for PostgreSQL - Flexible Server instance.
The traffic flow is as follows: Client applications send their PostgreSQL connection requests to the public or private IP address of the Azure Load Balancer. The Load Balancer then distributes these requests across the healthy PgBouncer instances in its backend pool. Each PgBouncer instance, in turn, manages a pool of connections to the backend Azure PostgreSQL Flexible Server.
(Conceptual diagram of Clients -> Azure LB -> PgBouncer instances (VMs or AKS Pods) -> Azure PostgreSQL Flex Server)
6. Resilience in Action: Failover & Recovery
The true strength of this distributed PgBouncer architecture, fronted by Azure Load Balancer, shines during failure events.
PgBouncer Instance/Pod Failure: If a PgBouncer VM becomes unresponsive or a PgBouncer pod in AKS fails its health checks, the Azure Load Balancer (or Kubernetes service) automatically detects this via its configured health probes. It swiftly stops routing new client connections to the unhealthy instance and directs them to the remaining healthy PgBouncer instances in the backend pool. This ensures the pooling layer itself remains available with minimal to no perceived disruption for new connections, maintaining application continuity.
Azure PostgreSQL Flexible Server Failover: When your Azure Database for PostgreSQL - Flexible Server instance undergoes a failover (manual or automatic if HA is configured), existing backend connections from PgBouncer instances will be terminated. PgBouncer will then attempt to re-establish connections. Properly configured server_check_query and DNS resolution settings within PgBouncer help in quickly detecting the new primary. While PgBouncer manages this reconnection, client applications might experience transient errors and should implement robust retry logic to seamlessly handle this brief period.
Zone Outages: By strategically deploying your PgBouncer VMs (or AKS nodes) and your Azure PostgreSQL Flexible Server (with HA) across multiple Availability Zones, you significantly enhance resilience against datacenter-level failures, ensuring the entire database access path can withstand a zone-specific outage.
7. Conclusion and Proof of Concept
Architecting multiple PgBouncer instances behind an Azure Load Balancer transforms your connection pooling layer from a potential bottleneck or single point of failure into a robust, scalable, and highly available gateway to your Azure Database for PostgreSQL - Flexible Server. This approach is essential for mission-critical applications demanding consistent uptime, optimal performance, and graceful scalability.

Comments
Post a Comment